|
|
|
This page is obsolete. Please try Apache Sedona instead.
This example provides how to use Apache Spark with NASA HDF data products. Apache Spark is in-memory cluster computing framework. There are many ways to use Apache Spark with NASA HDF products. For partitioning, you can use Apache Hadoop by splitting HDF files or use RDDs in Python or Scala. You can also use different languages that Apache Spark supports such as R and Java.
This example page explains various workflows that Earth Science user may face and illustrates how to use Apache Spark effectively for each workflow with NASA HDF products.
Spark installation requires Java. If your system doesn't have Java, please install the latest Java first.
If you are a Mac user, using brew will be easiest way to install Spark.
If you are a Python user, you can use pyspark-notebook Docker file. Since the Docker file installs only h5py, please use conda install pyhdf to access HDF4 files from your Docker instance.
h5spark allows you to access HDF5 in Scala and h5spark author demonstrated that Scala performed much faster than Python. Thus, we provide Scala examples first.
Since there's no Scala APIs for reading HDF files, the h5spark uses JNI-based HDF-Java to access data. The example code in the original h5park is slightly outdated because latest HDF-Java uses a different package name. The modified example code is available here.
Since there's also HDF-Java API for HDF4 files, you can use this Scala example program to replace the above h5spark's HDF5 reader.
If you'd like to access HDF using pure Java without relying on JNI, Unidata's netCDF-Java-based reader is implemented in SciSpark and the pure Java reader is refined to read individual dataset. Like h5spark, SciSpark also uses RDDs.
This blog explains how to work with NASA HDF-EOS5 data in detail using Python binding of Spark. You can create Spark RDDs following the h5py example for HDF5 data and the pyhdf example for HDF4 data.
Spark also supports Pandas data frame and Pandas can read HDF5 file directly or binary file using the HDF4 file content map. The drawback is that Pandas works only with tabular data in HDF5 compound data types.
PySpark can read/write Apache Parquet format easily to and from HDF5 if your dataset in HDF5 file is accessible by Pandas HDFStore.
If Pandas doesn't support your dataset in HDF, Apache Arrow provides a bridge that can convert datasets from HDF4/HDF5 files via pyhdf/h5py and Pandas. Here's a complete example that converts HDF5 dataset using PyArrow. Please note that Apache Arrow project is still under development so installation is not straightforward and too difficult to cover everything here.
Once dataset is converted, you can easily read Parquet file directly using Spark SQL in Scala.
R is similar to MATLAB. R binding for Spark, SparkR, provides a very convenient way to convert HDF5 file into Parquet file.
Unfortunately, there's no HDF4 reader for R. However, you can use GDAL to read HDF4. Simply build GDAL library with HDF4 support and link the library with rgdal package by building from source.
This section is for advanced users who are familiar with programming and internals of HDF file formats. This solution will be particularly useful for NASA swath data users when they are searching for granules based on lat/lon location of their interest.
HDF4 file content map can generate full offset/length information. Since Spark supports reading binary input, it is possible to process HDF4 data without relying on HDF-Java JIN library and HDF4 library underneath. This solution is quite attractive because it doesn't require the installation of HDF4 software stack and can be integrated with Elastic Search.
The following figure illustrates the overall architecture of reading HDF as pure binary file using HDF maps.
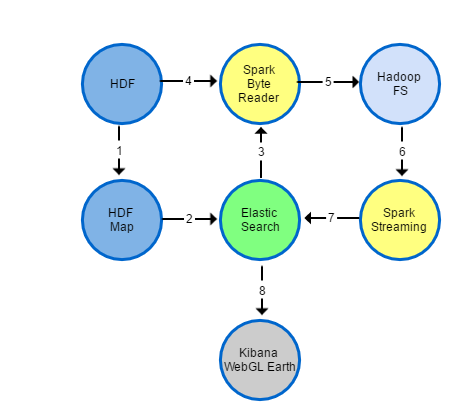
In the above diagram, the key components are highlighted in yellow circle. The example program for Spark Byte Reader (step 4 & 5 in the above diagram) is available here and the example program for Spark Streaming (step 6 & 7) is available here.
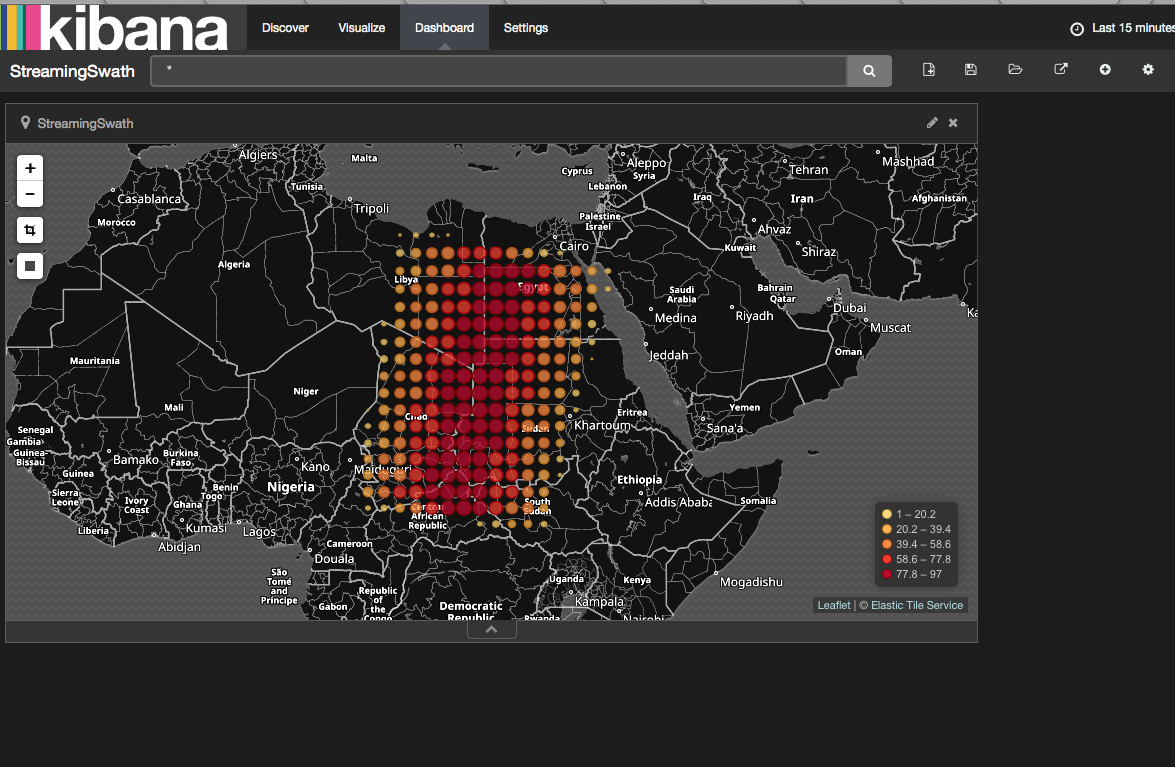
The use of Elasticsearch storing Spark processing results allows you to visualize HDF data easily using dash board such as Kibana and HTML5 WebGL Earth with web browser (no special tool like Panoply is necessary). The visualization through dash board using streaming data is useful to spot anomaly (e.g., hurricane / fire) quickly using near real-time NASA data.
For example, you can use Kibana dash board to visualize data in Elastic Search as shown in the screenshot below.
Similarly, you can use HTML5 WebGL Globe as shown in the screenshot below.